Consider static typing
Contents
Introduction
Matz, the designer of Ruby, always gives the RubyConf opening keynote, and at RubyConf 2014 he announced his ambitions for the next major version of the language. He said that Ruby 3.0 may happen in the next ten years, and that he’s thinking about three main topics in its design: new concurrency features, a just-in-time compiler (perhaps the LLVM JIT), and static typing.
That’s right: static typing! A lot of people were worried when they heard that, which is understandable; in the Ruby community we don’t get much exposure to static type systems, and they immediately make us think of languages like C and Java. So I want to unpack Matz’s remarks a bit, and provide a bit of context and vocabulary around them, in the hope of encouraging a productive conversation about static typing in Ruby.
My interpretation is that Matz proposed three specific ideas beyond just “Ruby should have static typing”, namely:
- structural typing,
- implicit typing and
- soft typing.
Those ideas provide an important degree of subtlety that would steer the language towards something very different from Java-flavoured-Ruby.
If you already know what all those words mean, then great, I don’t have anything else to tell you. But if they’re new to you, I’d like to convince you that they represent interesting ideas which go beyond the features of the static type systems you’ve used in the past, and therefore might be interesting to think about in the context of Ruby. Or hey, maybe not — maybe they’re worthless! — but let’s at least be specific about what we’re considering.
Values
As a way into this subject, I’d like you to think about how computers handle values. Imagine you could crack open your laptop or your smartphone, zoom in to the microscopic level, and peer into its memory to see what was stored there.
You’d see something like this, an undifferentiated soup of ones and zeroes:
11011010 01101100 11101101 01101101 11011111 11011011 00010100 11010010 10101101 01100001 10010010 00100101 01110111 10110110 01101101 11011011 11011010 10110111 10110101 00100101 00010011 11111101 10100010 10010101 01111011 01110100 00010010 11001101 11011010 10010100 01101101 11110110 11010101 01010010 00100110 10010101 00010111 11101101 10000111 01001010
What do those bit patterns mean? You can’t tell just by looking at them; they don’t have any inherent meaning, at least not an interesting one.
So at the lowest level, every value inside a computer looks the same, just a pattern of ones and zeroes. But when we write code to manipulate a value, we usually have a specific interpretation in mind: a particular pattern of bits might represent an unsigned or signed integer quantity, a floating-point quantity, a letter of the alphabet, the integer address of a memory location where some data structure is stored, and so on.
Primitive operations inside a computer generally assume that their arguments are supposed to be interpreted in a particular way. For example, at some level a computer will have different operations for “add two integers” and “add two floating-point numbers”, because every pattern of bits has a different meaning depending on whether it’s being interpreted as an integer or a floating point number, so the result of “adding” two patterns of bits will be different too.
If we add two 32-bit patterns of ones and zeroes by interpreting them as unsigned integers, we get a particular result:
00111111 10000000 00000000 00000000 (= 1065353216) + 01000000 00000000 00000000 00000000 (= 1073741824) = 01111111 10000000 00000000 00000000 (= 2139095040)
(The standard representation of integers in computers has been chosen so that the operation of adding them is just simple bitwise addition.)
If we add the same two patterns by interpreting them as floating-point numbers, we get a different result:
00111111 10000000 00000000 00000000 (= 1.0) + 01000000 00000000 00000000 00000000 (= 2.0) = 01000000 01000000 00000000 00000000 (= 3.0) ≠ 01111111 10000000 00000000 00000000
(The procedure for adding floats is more complicated than just summing the bits in each column.)
Of course, if those bits represent something that’s not an absolute quantity, like a memory address or timestamp, it might not make sense to add them at all.
This points to a fundamental problem in constructing computer programs: how do we avoid values being accidentally misinterpreted? If we store in memory some binary data that represents an unsigned integer, and later retrieve that data and mistakenly assume that it represents a floating point number or a pointer to a particular kind of data structure, the result of our program will be junk.
To a first approximation, the machine code that actually gets executed by CPUs doesn’t get involved in this issue at all, and nor does the assembly language we use to generate it. Here’s an example in ARM assembly:
ADD R0, R1, R2
LDR R0, [R1]
LDF F0, [R1]
STR R0, [R2, R1]
MOV PC, R1Each register contains an interpretation-agnostic pattern of bits — a word — and these instructions respectively treat the same contents of register R1 as an integer, then as the address of an integer, the address of a floating point number, a relative integer offset of some other address, and as the target address of a branch.
Early higher-level programming languages stayed out of it too. Here’s a program written in one of them:
GET "LIBHDR"
LET START() = VALOF $(
FOR I = 1 TO 5 DO
WRITEF("%N! = %I4*N", I, FACT(I))
RESULTIS 0
$)
AND FACT(N) = N = 0 -> 1, N * FACT(N - 1)This language is BCPL, a direct ancestor of C, and it’s ultimately a kind of portable assembly language: each value is a word of bits, and those bits get interpreted differently depending on which operator you use with them. In this factorial program, the variables I and N are populated with words representing integers, and they happen to be consistently used as arguments to integer multiplication and subtraction operators, which correctly treat their contents as integers, so everything works fine.
But in the same program we could just as well add I and N together while treating them as floating point numbers with the #+ floating point addition operator, to get a nonsense result:
LET X = I #+ NOr we could multiply N by a floating point number with the #* operator, again producing nonsense because N’s contents represent an integer:
LET Y = N #* 3.14Or we could even treat N as a pointer, interpreting its contents as a memory address to read from or write to, which would almost certainly be a disaster:
LET Z = !N
!N := 1.2 * 3.4(Even the two floating point literals are being incorrectly multiplied with the * integer multiplication operator to give a junk answer.)
Assembly and BCPL have the same full computational power as other languages, of course, but they rely completely on the programmer to keep a mental model of which values should be interpreted in which ways, and to make sure that every use of an operation is appropriate for the values it’s being applied to.
Metadata about values
Which brings us to type systems. Type systems are a programming language technology designed to prevent this kind of error. Incorporating a type system into a language allows us to constrain, or perhaps eliminate completely, the ability of the programmer to accidentally write code that misinterprets a value.
Broadly speaking, a type system is a set of rules that expects some of the things in your program to have pieces of metadata attached to them. I’m being intentionally vague here, because the exact meaning of “thing” and the exact content of the metadata depends on the particular type system. But regardless of the details, those pieces of metadata are called types, and they provide information about the intended interpretation of whatever they’re attached to.
A type system’s rules describe how to check this metadata to prevent errors caused by misinterpretation. The general idea is to take the implicit information about value representation out of the mind of the programmer and put it into the computer as explicit metadata — make it part of the program somehow — so that it can be systematically checked for consistency with the operations used on those values.
The design of type systems can get very complicated, but it involves answering three main questions:
- Firstly, where does the metadata go? That is, what are the mysterious “things” in your program that types get attached to?
- Secondly, what does that metadata look like? What information does a type tell us about how to interpret a value?
- And finally, where does that metadata come from? Who decides how values should be interpreted?
Where the metadata goes
Let’s begin with the first question. Where does the metadata go? There are three main answers we see in the wild.
Nowhere
The simplest possible answer is that the metadata goes nowhere: programs don’t have any metadata at all, as we saw with assembly language and BCPL. Programming languages that do this are usually called untyped.
On values
Another popular answer is that the metadata goes on values. That means that our actual in-memory representation of values includes extra information about how they should be interpreted. Once we have a convention about how to read that information, the programming language’s operations can check it to make sure they’ve been given compatible arguments. The rules of the type system are therefore built into the language’s runtime — its interpreter, or its bytecode virtual machine, or whatever.
Ruby falls into this category. The C implementation of the official Ruby interpreter, MRI, defines a data structure called RBasic:
typedef unsigned long VALUE;
struct RBasic {
VALUE flags;
const VALUE klass;
}An RBasic structure contains a collection of flags which record whether a value is a string, a regular expression, an array, an instance of a user-defined class, and so on:
enum ruby_value_type {
RUBY_T_NONE = 0x00,
RUBY_T_OBJECT = 0x01,
RUBY_T_CLASS = 0x02,
RUBY_T_MODULE = 0x03,
RUBY_T_FLOAT = 0x04,
RUBY_T_STRING = 0x05,
RUBY_T_REGEXP = 0x06,
RUBY_T_ARRAY = 0x07,
RUBY_T_HASH = 0x08,
RUBY_T_STRUCT = 0x09,
RUBY_T_BIGNUM = 0x0a,
RUBY_T_FILE = 0x0b,
RUBY_T_DATA = 0x0c,
RUBY_T_MATCH = 0x0d,
RUBY_T_COMPLEX = 0x0e,
RUBY_T_RATIONAL = 0x0f,
RUBY_T_NIL = 0x11,
RUBY_T_TRUE = 0x12,
RUBY_T_FALSE = 0x13,
RUBY_T_SYMBOL = 0x14,
RUBY_T_FIXNUM = 0x15,
RUBY_T_UNDEF = 0x1b,
RUBY_T_NODE = 0x1c,
RUBY_T_ICLASS = 0x1d,
RUBY_T_ZOMBIE = 0x1e,
RUBY_T_MASK = 0x1f
};Every Ruby object begins with an RBasic structure that contains these flags. Here are a few examples:
struct RString {
struct RBasic basic;
union {
struct {
long len;
char *ptr;
union {
long capa;
VALUE shared;
} aux;
} heap;
char ary[RSTRING_EMBED_LEN_MAX + 1];
} as;
};
struct RArray {
struct RBasic basic;
union {
struct {
long len;
union {
long capa;
VALUE shared;
} aux;
const VALUE *ptr;
} heap;
const VALUE ary[RARRAY_EMBED_LEN_MAX];
} as;
};
struct RRegexp {
struct RBasic basic;
struct re_pattern_buffer *ptr;
const VALUE src;
unsigned long usecnt;
};
struct RObject {
struct RBasic basic;
union {
struct {
long numiv;
VALUE *ivptr;
struct st_table *iv_index_tbl;
} heap;
VALUE ary[ROBJECT_EMBED_LEN_MAX];
} as;
};(RObject is used to store instances of user-defined classes.)
MRI defines some convenient macros and helper functions that can extract these flags from any value:
#define TYPE(x) rb_type((VALUE)(x))
static inline int
rb_type(VALUE obj)
{
if (IMMEDIATE_P(obj)) {
if (FIXNUM_P(obj)) return T_FIXNUM;
if (FLONUM_P(obj)) return T_FLOAT;
if (obj == Qtrue) return T_TRUE;
if (STATIC_SYM_P(obj)) return T_SYMBOL;
if (obj == Qundef) return T_UNDEF;
}
else if (!RTEST(obj)) {
if (obj == Qnil) return T_NIL;
if (obj == Qfalse) return T_FALSE;
}
return BUILTIN_TYPE(obj);
}
#define BUILTIN_TYPE(x) (int)(((struct RBasic*)(x))->flags & T_MASK)These give MRI a way of checking a value’s type before performing an operation on it. If the type is unsuitable for the operation being performed, the runtime can report an error and exit gracefully instead of giving a junk result.
Programming languages that put metadata on values are called dynamically typed. We use the word “dynamic” because we can’t see the types by looking at the inert program text; they appear on-the-fly in memory when that program is run.
On source code
The third main answer to “where does the metadata go?” is: on pieces of source code. Rather than store metadata on values in memory when the program is running, we can put it in the actual text of the program, as part of the syntax of expressions and statements. Under this regime, the rules of the type system are built into the language’s compiler — or, in an interpreted language, the bytecode compiler or whatever other part of the interpreter deals with turning raw source code into an executable internal representation.
This is how a language like C works. In the source of a C program we write things like int, long and void to declare the types of variables, function parameters and function return values:
#include <stdio.h>
long factorial(int n) {
long result = 1;
for (int i = 1; i <= n; ++i) {
result *= i;
}
return result;
}
int main(void) {
int n;
scanf("%d", &n);
printf("%d! = %ld\n", n, factorial(n));
}This kind of type system has rules which allow all the syntactic occurrences of variables and function calls to be checked to make sure the metadata from their declaration matches up with what’s expected in the place they’re being used. If you get a single detail wrong, your program won’t even compile.
These are called statically typed programming languages. We don’t need to run a statically typed program to check its metadata, because it’s written right there in the source code. In the simplest case (e.g. C), that metadata disappears completely by the time the program is run; in reality, many “statically typed” languages (e.g. Java) have metadata that sticks around at run time, resulting in a subtler mix of static and dynamic typing.
Consequences: freedom versus safety
So those are the three main ways of answering the question: there is no metadata, or metadata gets attached to values, or metadata gets attached to pieces of source code.
There’s a spectrum of increasing safety here. If your program interprets a value wrongly, a static type system can tell you about your mistake at compile time before you ever run the program; a dynamic type system can tell you at the exact moment of misinterpretation, during the execution of the program; and an untyped language will just obediently produce garbage and never complain. (The “where?” question is really a proxy for asking when the metadata gets checked — compile time, run time, never — but that simplification is good enough for this discussion.)
Virtually all mainstream programming languages have some kind of type system, whether static or dynamic, because it’s easy for value misinterpretation to silently ruin the behaviour of a program, so it’s important to do something to protect against it.
Telling compilers and runtimes about the meaning of values can’t prevent subtle errors of logic or design, but it does eliminate a whole class of silly mistakes. Robin Milner’s famous “well-typed programs cannot go wrong” slogan captures something useful about the main benefit of type systems, although it does rely on a narrow definition of what “going wrong” means.
Safer is better, all else being equal, and static type systems are safer than dynamic ones because they catch mistakes earlier. Unfortunately all else isn’t equal, and extra safety comes at a price: static type systems are conservative. In general it’s impossible to tell what a program will do without running it, so static type systems sometimes have to make guesses about run time behaviour, and it’s important that those guesses are themselves safe.
If it’s unclear whether a program contains any value-interpretation errors, the safe option is to report that it does. This conservatism means that sometimes a perfectly healthy program will be rejected by a static type system — the programmer can see that it’s error-free, but the type system isn’t sophisticated enough to agree. Simon Peyton Jones calls this the Region of Abysmal Pain: the inevitable gap between “the programs we want to write” and “the programs that the static type system will let us write”.
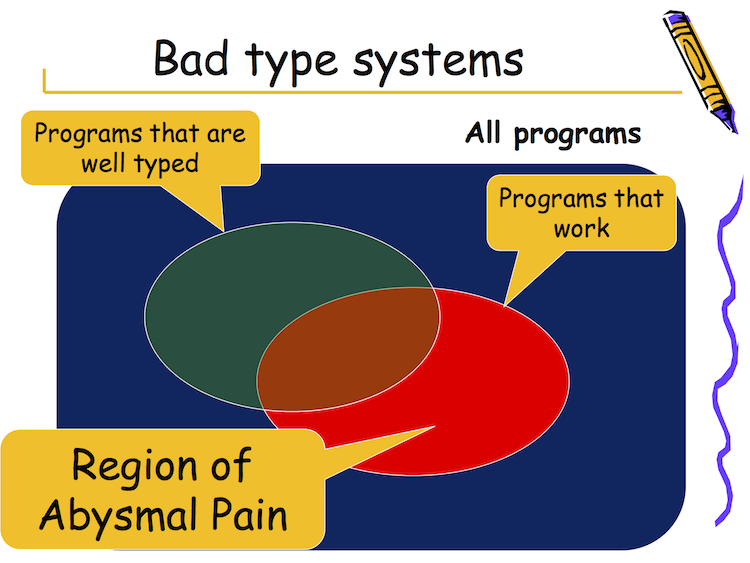
To some extent, then, all languages have to trade freedom for safety. Untyped languages let us write absolutely any program we want to, and it’ll be blindly executed without regard for correctness; dynamically typed languages let us write only those programs which don’t actually cause misinterpretation errors at run time; and statically typed languages let us write only programs that can be shown at compile time not to contain such errors.
What the metadata looks like
The second big question about metadata was: what does the metadata look like? This question is independent of whether the types are static or dynamic; it’s about deciding what kind of information we want to record about how to interpret values, regardless of where we record it.
Names
Most type systems you’ve seen are probably nominal type systems. This means that types are just names, like in the C code we saw earlier, which uses names like int, long and void to identify the types of values. This is by far the most common kind of metadata; it’s what you’re used to seeing in C, C++, Java, and virtually all mainstream programming languages, so I won’t go on about it here.
Structures
But there’s an alternative answer, which is that instead of types being simple names, they can be structures. Implicit in that answer is the idea that you can compare types by comparing their structures and deciding whether they’re compatible, rather than just checking whether or not two names are the same. This arrangement is called a structural type system.
Here’s an example of what I mean, written in the Go language:
type Shape interface {
Area() float64
}Go’s interfaces let us declare a type called Shape, and then say that a Shape is anything with a method called Area that returns a float64. This is the “structure” I’m talking about: although the Shape type does have a name for convenience, it’s not the name that’s important, it’s the structure that it refers to. (The structure here is a list of method signatures; other structural type systems support more complex structures.)
Once we have this interface type, we can invent other types that conform to it. Here are types called Rectangle and Circle that both have implementations of an Area method:
type Rectangle struct {
width, height float64
}
func (r Rectangle) Area() float64 {
return r.width * r.height
}
type Circle struct {
radius float64
}
func (c Circle) Area() float64 {
return math.Pi * c.radius * c.radius
}Neither Rectangle nor Circle explicitly mentions the Shape interface, but they have a matching structure. That means we can use Rectangle and Circle values wherever a Shape is expected:
func main() {
shapes := []Shape{
Rectangle{width: 6, height: 7},
Circle{radius: 8},
}
totalArea := 0.0
for _, shape := range shapes {
totalArea += shape.Area()
}
fmt.Println(totalArea)
}We don’t have to declare explicit inheritance, like in a nominally typed language; we can just use a Rectangle or Circle in place of a Shape, because the structure of Rectangle and Circle is in some sense compatible with Shape’s structure. (In this simple case the three structures are literally equal, but see below for a more subtle example.)
Consequences: explicit versus implicit subtyping
So those are two different answers to “what does the metadata look like?”: it could contain simple names like in C or Java, or it could be structured like some of the types in the Go, Scala and OCaml programming languages.
The important difference between nominal and structural typing is how subtyping is decided.
A type system repeatedly asks: is this value being interpreted correctly at this point in the program? In the case where types match exactly this is easy; if an operator is expecting a value of some type X, and it gets a value of type X, then that’s obviously okay because the types are equal.
But what if the actual value has some other type Y? Is that acceptable? It depends on how subtyping works.
One type is a subtype of another if it is substitutable for it, which means that a value of the subtype can be used in any situation where a value of the supertype is expected. In Ruby, say, we think of both Fixnum and Bignum as subtypes of Integer; if a method expects to be given an Integer argument, either a Fixnum or Bignum will work.
In nominal type systems, subtyping is declared explicitly. For example, Java names its types after classes and interfaces, so instances of a class A have the type “A”. The language allows a class A to extend another class B, making “A” a subtype of “B”; we could also have class A implements C, so that “A” becomes a subtype of “C” as well. Then a value of type “A” could be passed as an argument to any method that expects a parameter of type “B” or “C”.
But structural type systems work differently: subtyping is decided implicitly, based on whether the structure of two types is compatible — whatever “compatible” means for the particular language. In Flow, a static type system for JavaScript, we can say:
var fullName = function (person: { firstName: string; lastName: string }) {
return person.firstName + " " + person.lastName;
};
var captain = { firstName: "James", middleName: "Tiberius", lastName: "Kirk" };
console.log(fullName(captain));The fullName function expects an argument of the nameless type { firstName: string; lastName: string }, and although we pass it a value of the different type { firstName: string; middleName: string; lastName: string }, that’s okay because the latter type exhibits the “shape” we want; the longer type is a subtype of the shorter one.
Where the metadata comes from
Last big question: where does the metadata come from? This one only really applies in the context of statically typed languages, where information has to get attached to pieces of source code somehow; in dynamically typed languages we expect the operations themselves to put type information on values at the moment of their creation.
The programmer
The most obvious answer is that the programmer provides this information by explicitly annotating the source code; after all, the whole point is to capture knowledge from their brain. Remember our C factorial example:
long factorial(int n) {
long result = 1;
for (int i = 1; i <= n; ++i) {
result *= i;
}
return result;
}To get this code to compile, we have to actually peck out the strings “long” and “int” at every variable, function and parameter declaration while we write the program — or, if we’re lucky, get our editor or IDE to do it for us.
This is called manifest typing, and the majority of mainstream statically typed languages work in a similar way, expecting the programmer to do all (or most) of the annotation busywork.
The computer
The alternative is to allow the computer — usually the compiler — to add the type annotations itself. This sounds counterintuitive because we’ve been assuming that only the programmer knows how each value should be interpreted, but that’s an oversimplification: every time the programmer uses a particular operation (e.g. integer addition), they’re leaking incomplete information about what kind of values (e.g. integers) they’re expecting to see at that particular point in their code. For some carefully-designed languages it’s possible to use a type inference algorithm to move this partial information around, join it together, fill in the gaps, and eventually reconstruct complete type annotations for every expression in the program, sometimes without needing the programmer to label anything at all.
Look at this factorial program written in the Haskell language, as entered into its interactive GHCi console:
> let factorial n = if n == 0 then 1 else n * factorial (n - 1)
That looks more like a dynamically typed program than a statically typed one; it’s not very different from what we’d write in Ruby, Python or JavaScript. But it’s just as statically typed as the C version, because Haskell can infer all the type annotations just by looking at how we’ve used the ==, * and - operations and the 0 and 1 literals, so the type of every identifier is fully known before the code ever gets executed. (And we haven’t executed the factorial function yet, only defined it.)
Let’s ask GHCi what it knows about the static type of factorial:
>:type factorialfactorial :: (Num a, Eq a) => a -> a
That’s a bit daunting if you don’t know the language, but the “a -> a” part just means that factorial is a function which takes some type of value as an argument — Haskell’s invented the arbitrary name “a” for this type — and returns the same type of value as a result. The “(Num a, Eq a) =>” part means that the type a has to satisfy particular constraints: it must be numeric so we can use multiplication and subtraction on it, and it must also support being compared for equality, which isn’t number-specific behaviour. Seems reasonable, since that’s roughly what we could have worked out by looking at the code too, although the content of the types is more sophisticated than what we’ve seen previously.
And sure enough, if we call factorial with a value that satisfies those constraints, it works:
> factorial 5
120
If we try to call it with a value that doesn’t, we get a compile-time error before Haskell runs our line of code:
> factorial "hello"
<interactive>:
No instance for (Num [Char]) arising from a use of ‘factorial’
In the expression: factorial "hello"
In an equation for ‘it’: it = factorial "hello"
Using type inference to reconstruct source code metadata like this instead of requiring explicit annotations is sometimes called implicit typing.
Consequences: modularity versus convenience
We’ve already seen how static type systems have the general advantage of providing increased safety. They can also increase the performance of programs by eliminating the need to check for misinterpretation errors while the program is running; ideally, if a program passes the static type checker, it’s safe to assume that no values will be misinterpreted at run time.
The choice between making our static types manifest or implicit involves a trade-off between some other advantages too.
Implicit typing has the obvious advantage that it’s much more convenient to not have to write type annotations ourselves. If a language like Haskell can figure them out automatically, we can concentrate on writing actual executable code and save ourselves a lot of boring work.
However, implicit typing can only use the incomplete information that we reveal through our choice of operations; the programmer’s brain usually contains juicier ideas about the intended meaning of values, and type inference will (probably?) never be powerful enough to obtain that knowledge psychically.
One mundane advantage of writing explicit metadata in source code is that it becomes straightforwardly visible to both the computer and to other programmers, thereby serving as a kind of living documentation. Even if it doesn’t have a practical effect on the safety of the program, simple things like the careful choice of type names can go a long way towards making code easier to read and maintain.
Manifest typing also gives us a chance to decide exactly what types we want to expose between separate self-contained parts of our program. Controlling the amount of information that those parts reveal to each other through their interfaces is a powerful way of avoiding buggy edge cases and reducing unnecessary coupling.
For example, Haskell automatically inferred the type (Num a, Eq a) => a -> a for our factorial function, which seemed to work alright, but that “(Num a, Eq a) =>” constraint is also satisfied by floating-point numbers:
> factorial 5.0
120.0
Is that alright? Well, maybe — we never intended to be able to compute the factorial of a number that isn’t an integer, but it’s cool that it still works. Except when it doesn’t…
> factorial 5.1
*** Exception: stack overflow
There’s a problem here: our recursive factorial implementation assumes that its argument will eventually equal 0, but repeatedly subtracting 1 from 5.1 will never get us to 0, so the loop runs out of control until stack space is exhausted.
We could try to fix this with a different implementation:
>let factorial n = product [1..n]>:type factorialfactorial :: (Num a, Enum a) => a -> a
This function has a slightly different type: instead of “(Num a, Eq a) =>” we now have the constraint “(Num a, Enum a) =>”, which means that the type of the argument and return value should support sequential ordering instead of equality — essentially, it needs to be incrementable so that it can be used as the first element of a range — and it still needs be numeric because that’s what product expects. Fair enough.
At this point you might feel a little uncomfortable that factorial is leaking its implementation details like this, but hey, we’ve fixed the stack overflow:
> factorial 5.1
120.0
Oh, er, except that’s not the right answer. Look, we never wanted to get into all this in the first place! We only wanted a factorial for integers!
The problem here is that the inferred type is too general. Haskell’s inference algorithm understands the requirements of the individual operations we’re using, and it understands the shape of the plumbing that transports values between them, but it doesn’t understand what we meant when we wrote factorial; the implications of those operations’ combined behaviour when used together in this specific way are lost on it.
Fortunately, we can just come out and say what we mean with an explicit type annotation:
>let factorial :: Integer -> Integer; factorial n = product [1..n]>:type factorialfactorial :: Integer -> Integer
Now we’ve given Haskell the extra knowledge that we expect factorial to operate only on arbitrary-precision integers. The implementation is still the same, but its details have become hidden behind a more restrictive type. If we try to call this version with 5.1, we get a compilation error instead of the wrong answer:
> factorial 5.1
<interactive>:
No instance for (Fractional Integer) arising from the literal ‘5.1’
In the first argument of ‘factorial’, namely ‘5.1’
In the expression: factorial 5.1
In an equation for ‘it’: it = factorial 5.1
Brilliant! At last we’ve written a factorial that can’t give a wrong answer, because its implementation has been encapsulated behind a nice tidy type that precisely captures the kind of value we know how to handle.
> factorial (-5)
1
Oh, log off.
Anyway, hiding information like this is an effective way to contain knowledge within subsystems and make software more modular, which is a good thing. Of course, being able to put optional annotations into an implicitly typed system like Haskell’s gives us the best of both worlds, but implicit typing has a price: it requires a set of type inference rules in addition to the existing type checking rules, and inference is a harder problem because it involves synthesising new metadata rather than simply verifying what’s already there. Ideally all statically typed languages would have flawless type inference, but in practice that isn’t possible.
Possible Ruby 3.0 features
The purpose of this article was to unpack what Matz said, but I haven’t really talked about it yet. Now that we know about the various possible features of type systems, let’s have a quick peek at his slides and try to work out where he thinks Ruby 3.0 could sit in this large design space.
He does help us out by showing some speculative example code on this slide:
a=1 # type of a is IntegerAnd the next:
# x requires to have to_int
def foo(x)
print x.to_int
end
foo(1) # OK: 1 has to_int
foo("a") # NG: "a" does not have to_intThe following slide says:
-
Type is represented by:
-
Set of methods
- name
- number and type of arguments
- Class (as set of methods)
-
Set of methods
Taken together, this makes it pretty clear where Matz is going.
Static typing
Firstly, it’s obvious that he’s talking about Ruby’s type system being static, not just dynamic: metadata on pieces of source code, not only on run time values. There isn’t any guessing to do there because he came out and said it.
Structural typing
But he’s also clearly talking about using structural types, not just nominal ones: this slide says that the metadata should contain information about what messages a value responds to, not simply what class it’s an instance of; a type named after a class would just be a convenient shorthand for the set of method signatures from that class. That’s important because it would preserve some of the feel of duck typing; the type of a method argument can specify that it needs to respond to certain messages, and that constraint is satisfied (via implicit subtyping) by any object whose type says it responds to them.
Implicit typing
The code above doesn’t have any annotations, which suggests Matz wants a type system that uses type inference to automatically generate as much of the static metadata as possible, instead of making programmers write it explicitly. He also had an entire slide saying “type inference” so, er, that’s a pretty good clue too.
Soft typing
So, that much is fairly plain, but how would this implicit, structural, static type system actually work? Bringing those ideas together in the presence of Ruby’s existing features is a highly detailed and difficult job. For example, integrating structural typing with open classes is hard, because if new methods can be added to (say) the String class at any time while the program is running, how do you know what set of method signatures to put in the String type?
Matz made a couple of references to a paper from 1991 called “Soft Typing”, based on a PhD thesis from the same year. The paper and thesis describe a “best of both worlds” type system that works by transforming a program at compile time: a type inference algorithm tries to reconstruct static types for the whole program, and in the parts where it fails, it forces those parts to become statically typed by inserting dynamic checks. This turns a situation like “these two values may or may not be numbers” into “you can safely proceed on the assumption that these two values are numbers, because an exception will be thrown at run time if they’re not”.
This sounds appealing, but reading the thesis made me sceptical of how its ideas could be applied to Ruby, for a few reasons:
The soft type system is defined for an “idealised functional language”, namely a very simple toy language that doesn’t exhibit any of Ruby’s interesting features (e.g. objects). A subsequent paper adapted the same ideas to work with R4RS Scheme — not a toy, but also still a long way from being Ruby-like.
While it does feature a clever type inference algorithm, the soft type system doesn’t look structural to me, so it doesn’t seem like it helps with that particular design goal.
It doesn’t actually provide any safety. The main goal of soft typing is to improve performance by eliminating run time checks; instead of having a fully dynamic program, parts of it can be made statically typed, so that only the remaining “untypeable” parts need to be checked when it runs. But Matz said that we don’t need static typing for speed, citing how successful the V8 and LuaJIT projects have been at making dynamically typed languages (respectively JavaScript and Lua) run quickly, which leaves me confused about what benefits soft typing would bring to Ruby.
Now, I’m not an expert, so all of the above should be taken with a huge pinch of salt. Matz did go on to say that he was considering soft typing for only a restricted subset of Ruby, and wouldn’t attempt to make it work with #require, #define_method or #method_missing, with the intention that the language could “fall back to dynamic typing” “when soft typing is not applicable”, which would presumably eliminate some of the trickier challenges. It’s also possible that he’s thinking of allowing Ruby developers to inspect this transformed program as part of our workflow, so that we can get feedback from the static types where the inference algorithm has succeeded and pay cautious attention to the dynamic checks where is hasn’t.
That all sounds very plausible! But, again, I expect the devil to be in the details, and doubtless Matz would be the first to admit that no details exist yet.
What next?
What’s the next step? What, if anything, should the Ruby community do to start making progress on this?
We have a big challenge ahead of us: can we bring the safety, performance and documentation benefits of static typing to Ruby without compromising its flexibility, its friendliness, its humanity? Is there a way to keep the region of abysmal pain as small as possible, and keep it out of everyday Ruby programming altogether?
My technical opinion is that we can do it, and my non-technical opinion is that we should do it if we want Ruby to remain competitive and relevant in the next decade.
Almost all new languages have some kind of static type system; Rust is a good example of a recent language that’s not only statically typed, but which also pushes the boundaries of mainstream type systems by including an ownership system for statically tracking which part of the program is responsible for each allocated region of memory. Facebook released Flow just over a year ago, which is turning out to be a very capable static type checker for JavaScript. Even Perl 6 has optional support for static types.
There’s no point in Ruby being fashionable just for the sake of fashion, but these new languages are servicing a genuine and growing demand for computers to understand our programs better so they can help us to get them right and make them fast. As Matz said, we need to keep moving forward, or we’ll die; we have to feed the existing community, and continually attract a new one. Investigating a novel static type system seems like a good way of doing that.
Why should we even be interested, when we’ve all been using Ruby quite happily without ever needing static types? After all, many of us came to Ruby specifically to escape the barren, statically typed wastelands of Java and C++.
For me, safety and software quality is the most important reason. Imagine being able to catch a broken view helper the first time your Rails application boots on the CI server, instead of when someone hits an obscure page on the admin interface two weeks after it’s been deployed to production. Writing tests is great, but a static type system is like a built-in test suite that catches all the ridiculous, pointless problems you waste time on every day, so that you can focus on the interesting ones.
We have no reason to fear types. Ruby already has them; they already get checked. The only question is when they should be checked, and the earlier we can check them, the more likely it is that we’ll be able to catch silly mistakes before they make it into production. And that’s unequivocally a good thing, as long as we can come up with a static type system that understands the kind of programs we want to be able to write in Ruby.
These are hard problems, though. Designing a static type system that captures enough safety to be useful, while preserving enough flexibility to still feel like Ruby, is a serious formal challenge. The soft typing paper doesn’t provide the answers for a Ruby-like language, and besides, it’s not going to be a question of bolting on something that someone else has already made.
By all means let’s have a good look around; gradual typing is worth investigating, since it’s worked well for Flow, and there must be other ideas that we can beg, borrow or steal from the “static types for dynamic languages” research community. But ultimately I don’t know of anything we can take off the shelf here. Many of the pieces exist, but to fit them all together in the specific context of Ruby requires attention to mathematical detail as well as a sensitivity to Ruby’s aesthetic qualities. It’s going to take serious research, not brute-force hacking; the answer will probably look more like a PhD thesis than a pull request.
The job might be hard, but there’s no reason to be defeatist about it. There are plenty of smart and motivated people in the Ruby community; there are plenty of interested companies that have the money to pay research staff or fund a PhD studentship; there is plenty of desire to keep Ruby moving forward and make it a viable and relevant language for the next 10 years. I hope what I’ve said today can help to get those conversations started.